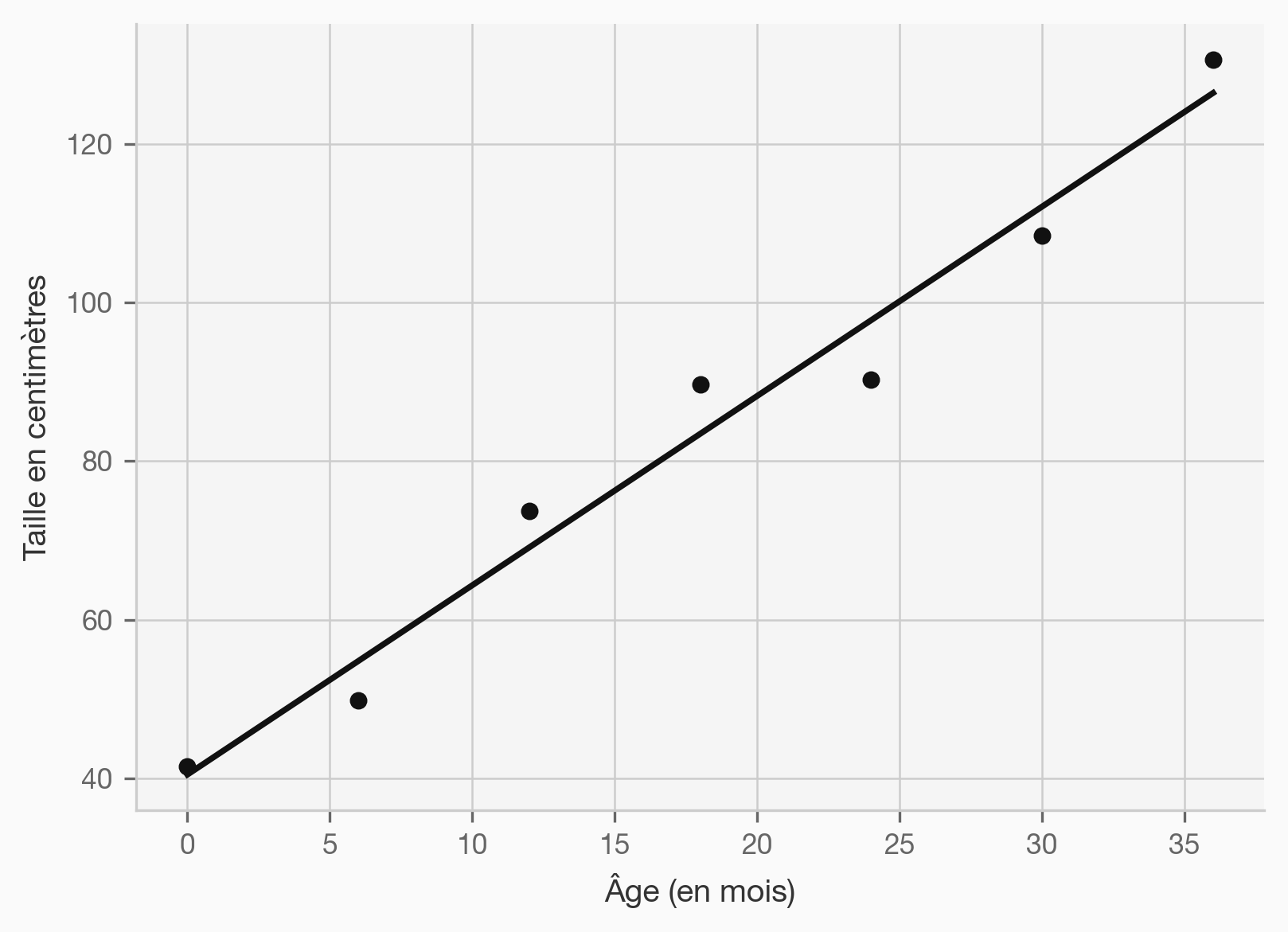
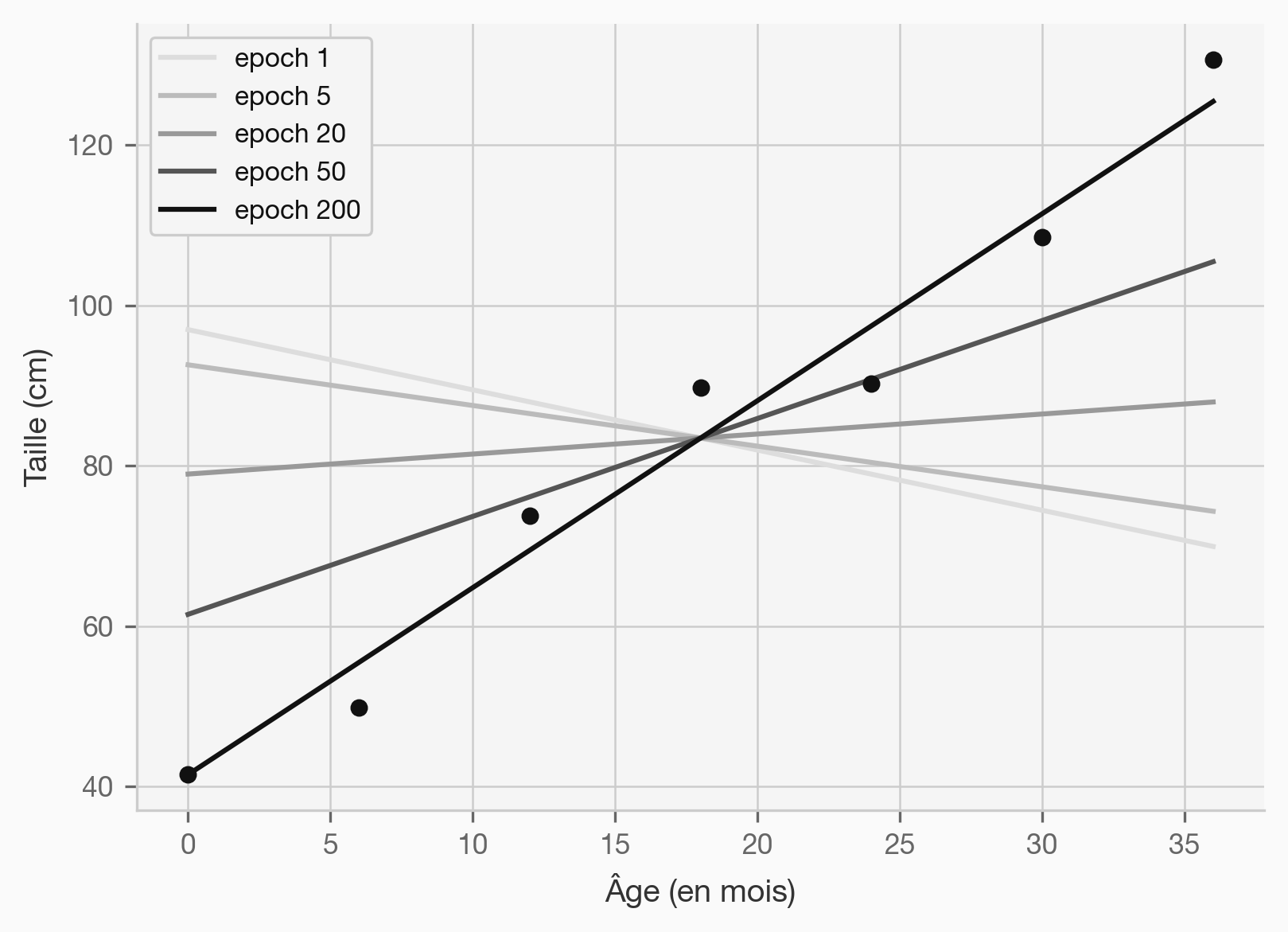
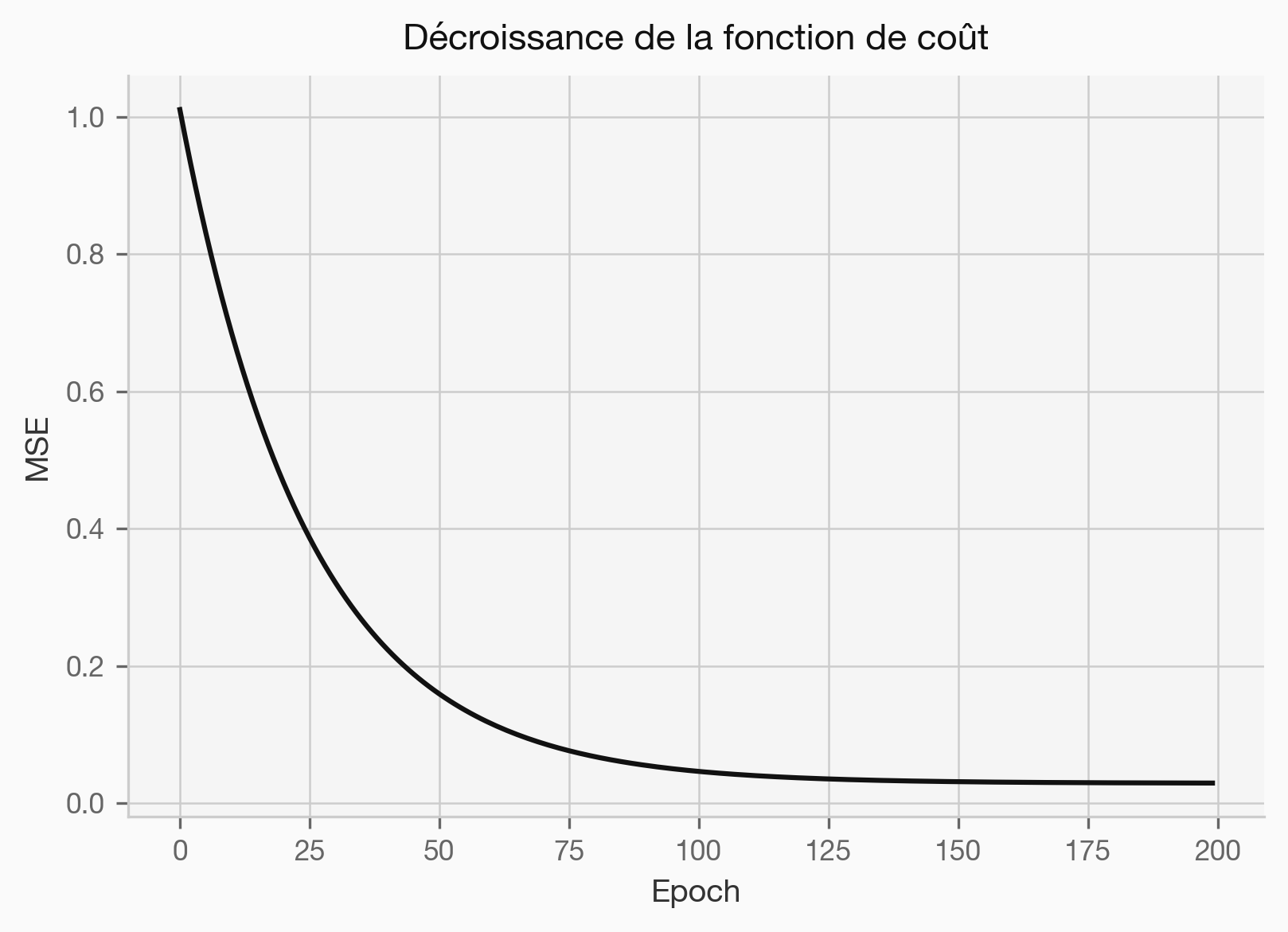
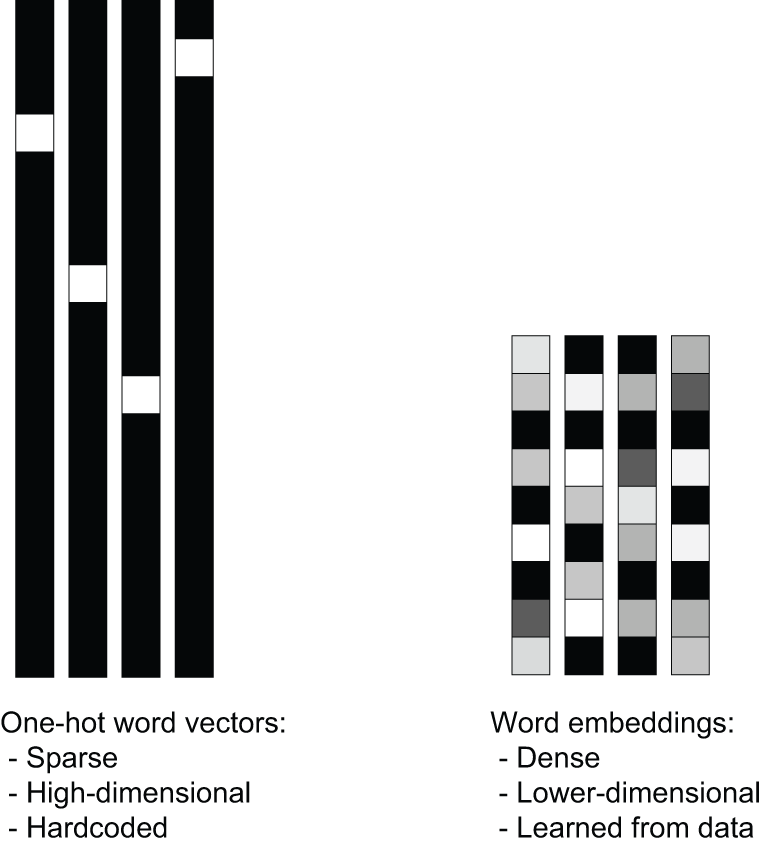
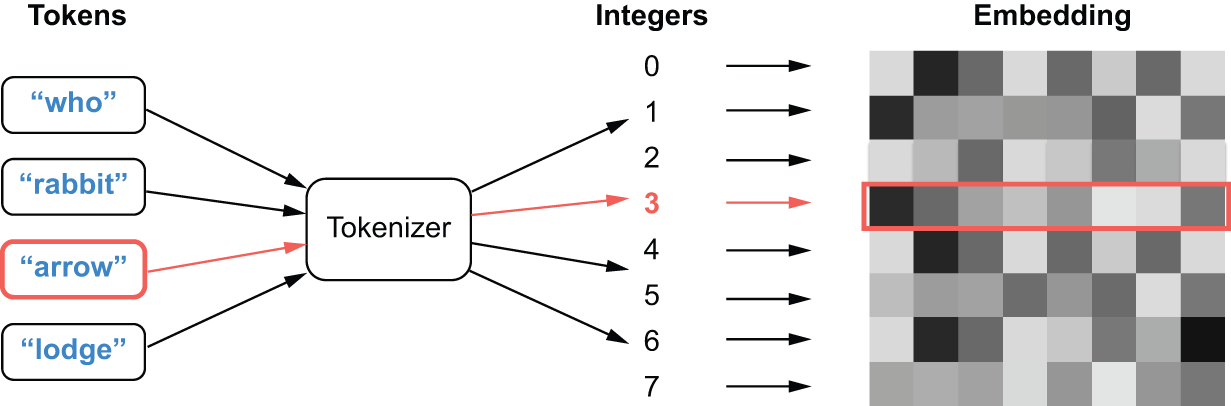
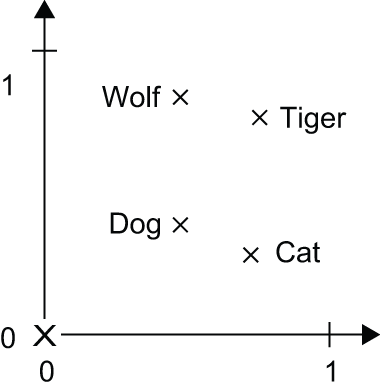
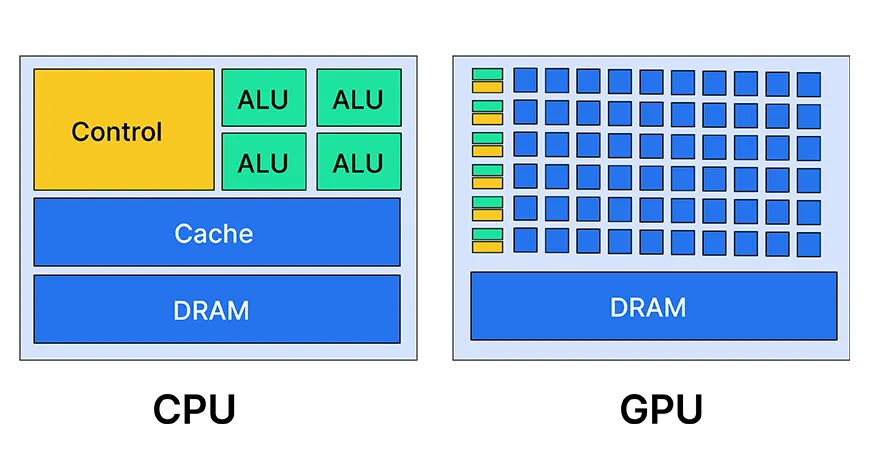
graph LR
subgraph X["x"]
x1["x₁"]
x2["x₂"]
x3["x₃"]
x4["x₄"]
end
subgraph C1["couche 1"]
n11["f"]
n12["f"]
n13["f"]
n14["f"]
n15["f"]
end
subgraph C2["couche 2"]
n21["f"]
n22["f"]
n23["f"]
end
subgraph C3["couche 3"]
n31["f"]
n32["f"]
n33["f"]
n34["f"]
end
subgraph Y["ŷ"]
y1["ŷ₁"]
y2["ŷ₂"]
y3["ŷ₃"]
y4["ŷ₄"]
end
x1 --> n11 & n12 & n13 & n14 & n15
x2 --> n11 & n12 & n13 & n14 & n15
x3 --> n11 & n12 & n13 & n14 & n15
x4 --> n11 & n12 & n13 & n14 & n15
n11 --> n21 & n22 & n23
n12 --> n21 & n22 & n23
n13 --> n21 & n22 & n23
n14 --> n21 & n22 & n23
n15 --> n21 & n22 & n23
n21 --> n31 & n32 & n33 & n34
n22 --> n31 & n32 & n33 & n34
n23 --> n31 & n32 & n33 & n34
n31 --> y1
n32 --> y2
n33 --> y3
n34 --> y4
style x1 fill:#F5F5F5, color:#111111, stroke:#111111
style x2 fill:#F5F5F5, color:#111111, stroke:#111111
style x3 fill:#F5F5F5, color:#111111, stroke:#111111
style x4 fill:#F5F5F5, color:#111111, stroke:#111111
style n11 fill:#111111, color:#FAFAFA, stroke:#111111
style n12 fill:#111111, color:#FAFAFA, stroke:#111111
style n13 fill:#111111, color:#FAFAFA, stroke:#111111
style n14 fill:#111111, color:#FAFAFA, stroke:#111111
style n15 fill:#111111, color:#FAFAFA, stroke:#111111
style n21 fill:#111111, color:#FAFAFA, stroke:#111111
style n22 fill:#111111, color:#FAFAFA, stroke:#111111
style n23 fill:#111111, color:#FAFAFA, stroke:#111111
style n31 fill:#111111, color:#FAFAFA, stroke:#111111
style n32 fill:#111111, color:#FAFAFA, stroke:#111111
style n33 fill:#111111, color:#FAFAFA, stroke:#111111
style n34 fill:#111111, color:#FAFAFA, stroke:#111111
style y1 fill:#F5F5F5, color:#111111, stroke:#111111
style y2 fill:#F5F5F5, color:#111111, stroke:#111111
style y3 fill:#F5F5F5, color:#111111, stroke:#111111
style y4 fill:#F5F5F5, color:#111111, stroke:#111111
style X fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style C1 fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style C2 fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style C3 fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style Y fill:#FAFAFA, color:#111111, stroke:#CCCCCC
linkStyle default interpolate basis