flowchart TD X["X"] --> F["f_θ(X)"] F --> Y["Y"] T["θ"] --> F style X fill:#F5F5F5, color:#111111, stroke:#111111 style F fill:#111111, color:#FAFAFA, stroke:#111111 style T fill:#EBEBEB, color:#666666, stroke:#AAAAAA style Y fill:#F5F5F5, color:#111111, stroke:#111111
Fonctionnement d’un LLM
Module IA · Cours 4
Denis Dréano & Raphaël Holzer
3MOC informatique · Gymnase du Bugnon
Planning du module IA
| Semaine | Cours (mardi) | TP (jeudi) | Lecture |
|---|---|---|---|
| Vacances d’hiver | — | — | — |
| 23 | Qu’est-ce que l’IA ? | Comparer des IA, prompt engineering | Exercice du blog |
| 24 | Histoire de l’IA | Installation et analyse d’un LLM | Lecture 2-3 |
| 25 | Cycle de vie d’un LLM | Fine-tuning d’un LLM | Lecture 4 |
| 26 | Fonctionnement d’un LLM | Entraînement d’un LLM | Lecture 5-6 |
| 27 | Développements récents et enjeux sociaux | — | Exercice |
| Semaine spéciale | — | — | — |
| Vacances de Pâques | — | — | — |
| 29 | Examen | — | — |
Cours 4 : Fonctionnement et entraînement d’un LLM
- Lien avec le programme de gymnase
- Fonctionnement et entraînement d’un LLM
- Cas général : Principe du machine Learning
- Réseau de neurones
- Tokenisation et Embedding
- Architecture Transformer
- Algèbre linéaire, GPU et géopolitique
- Conclusion
À quoi servent les maths et l’info de gymnase ?
Au Gymnase, vous avez appris les concepts de bases utilisés par l’IA :
- Programmation Python — Le langage de choix pour l’intelligence artificielle
- Architecture des ordinateurs — Comprendre le rôle des CPU, GPU, mémoire dans la performances des modèles
- Systèmes d’équations — Base des calculs dans les modèles
- Analyse — Chercher les minimum d’une fonction, dérivation
- Probabilités — Distribution du résultat d’un modèle, échantillonnage
Fonctionnement du machine learning
- Modélisation mathématique
- Entraînement
Notions de base du machine learning
Un modèle = une fonction à paramètres \(f_\theta\) :
\[Y = f_\theta(X)\]
- \(X\) : prompt, input, donnée, … de l’utilisateur
- \(Y\) : réponse, sortie, prédiction … du modèle
- \(f_\theta\) : Règle pour passer de l’input à l’output
- \(\theta\) : Variables qui paramétrisent les règles
Entrées et sorties
| Type | x | y | Exemples |
|---|---|---|---|
| text to text | prompt | réponse | chatGPT |
| text to image | prompt | image | MidJourney |
| text to video | prompt | video | Sora |
| classification d’image | image | classe | AlexNet |
| jeu de Go | disposition des pièces | coup suivant | AlphaGo |
| Protein folding | chaîne d’acides aminées | structure de protéines | AlphaFold |
flowchart TD X["X"] --> F["f_θ(X)"] F --> Y["Y"] T["θ"] --> F style X fill:#F5F5F5, color:#111111, stroke:#111111 style F fill:#111111, color:#FAFAFA, stroke:#111111 style T fill:#EBEBEB, color:#666666, stroke:#AAAAAA style Y fill:#F5F5F5, color:#111111, stroke:#111111
Données d’entraînement
Un modèle = une fonction à paramètres \(f_\theta\) :
\[Y = f_\theta(X)\]
- les paramètres sont déterminés par les données d’apprentissage
- les données consistent en des couples donnée d’entrée / donnée de sortie (\(X_i, Y_i\))
| Type | Données d’entrée \(X_1, X_2, ..., X_n\) |
Donnée de sortie \(Y_1, Y_2, ..., Y_n\) |
|---|---|---|
| text to text | morceau d’un texte rédigé par un humain | token suivant |
| text to image | description d’une image existante | image correspondante |
| text to video | description d’une vidéo existante | video correspondante |
| classification d’image | image d’une base de donnée | label donné par un humain |
| jeu de Go | disposition des pièces dans une partie de tournoi | coup suivant joué par le maître de go |
| Protein folding | chaîne d’acides aminées d’une protéine connue | structure de correspondante |
Fonction de coût
Un modèle = une fonction à paramètres \(f_\theta\) :
\[Y = f_\theta(X)\]
L’apprentissage consiste à trouver \(\theta\) tel que :
\[Y_i \approx f_\theta(X_i),\]
pour le maximum de couples de données \((X_i, Y_i)\).
En pratique, on doit déterminer une fonction de coût qui mesure une distance entre la prédiction du modèle \(f_\theta(X_i)\) et la vraie valeur \(y_i\), c’est-à-dire l’erreur du modèle.
\[\varepsilon_i = F_{\text{Coût}}(f_\theta(X_i), Y_i)\]
Exemple : La régression linéaire
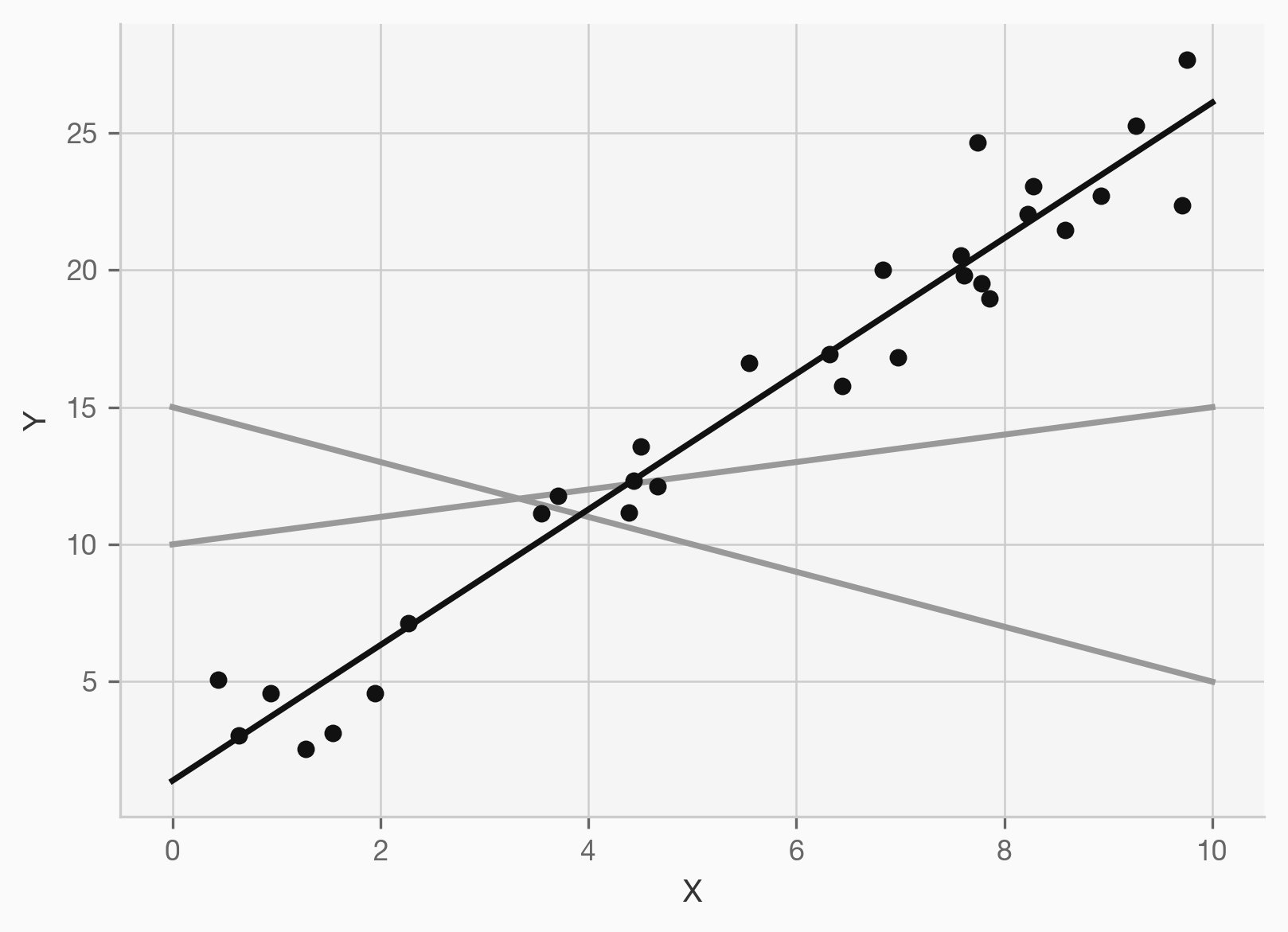
Modèle linéaire :
- Entrée : un nombre \(X\)
- Sortie : un autre nombre \(Y\)
- Données : des couples \((X_i, Y_i)\)
- Modèle : \(f_\theta(X) = a\cdot X + b\)
- Paramètres : \(\theta = (a, b)\)
- Fonction de coût : \[ \begin{align} \varepsilon_i &= F_{\text{Coût}}(f_\theta(X_i), Y_i) \\ &= (f_\theta(X_i) - Y_i)^2 \end{align} \]
Entraînement d’un modèle
Un modèle = une fonction à paramètres \(f_\theta\) :
\[Y = f_\theta(X)\]
Boucle d’entraînement :
- Tirer un batch \((X_i, Y_i)\) depuis les données
- Calculer la prédiction \(\hat{Y_i} = f_\theta(X_i)\) — forward pass
- Mesurer l’erreur \(\varepsilon_i = F_{\text{coût}}(f_\theta(X_i), Y_i)\)
- Ajuster \(\theta\) pour réduire \(\varepsilon_i\) — backpropagation
- Répéter
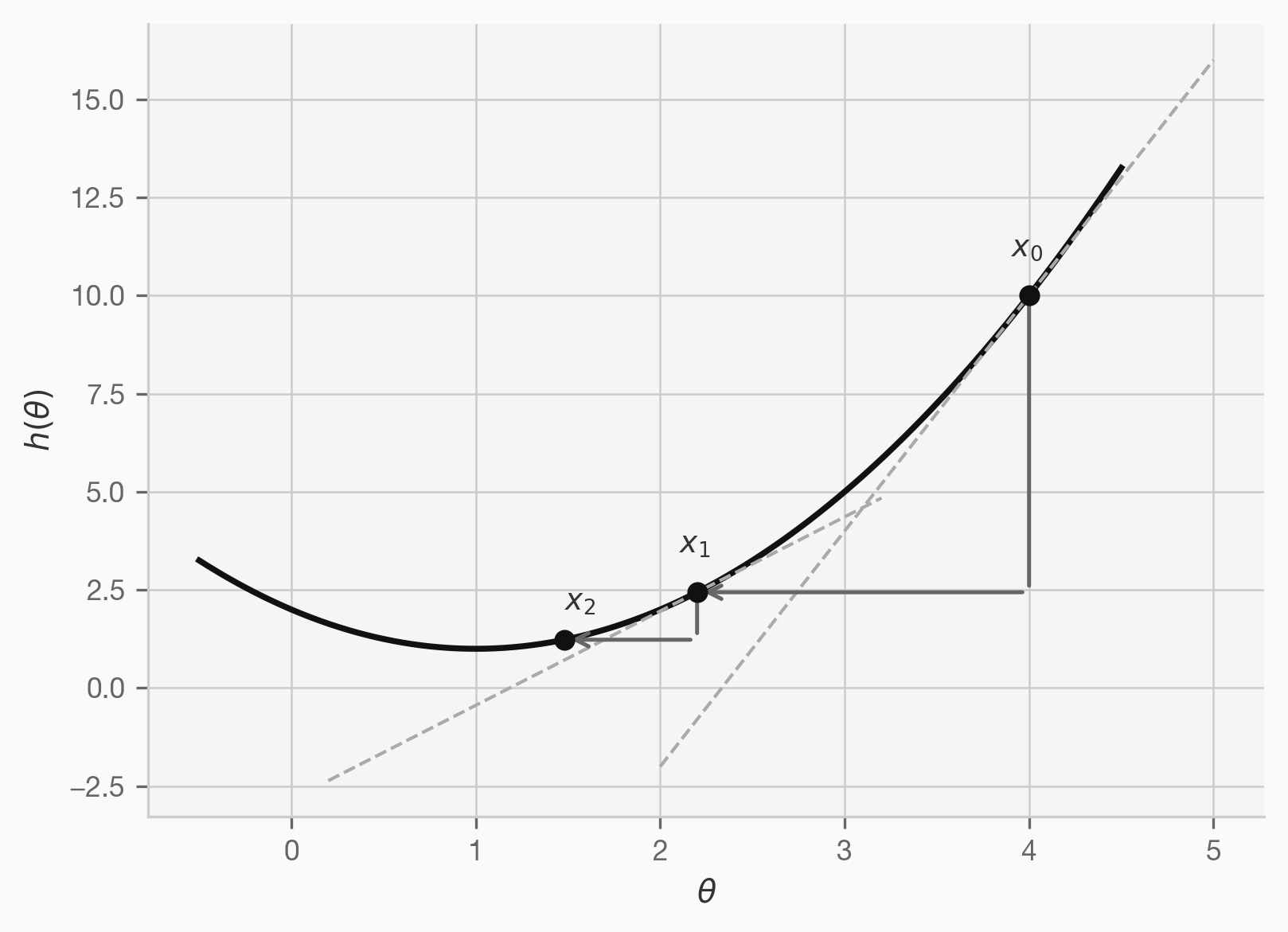
Ajustement des paramètres (poids)
Le principe d’ajustement des poids : dérivation de fonction et optimisation.
En dimension 1 :
- Inversion de variables : \(h(\theta) = F_\text{coût}(Y_i, f_\theta(X_i))\)
- But trouver le minimum : \(h'(\theta) = 0\)
- Problème : en général impossible à résoudre analytiquement
- Solution : algorithme d’optimisation numérique
En pratique \(\theta\) est un vecteur.
- La derivée se généralise au gradient
- Dans le cas d’un réseau de neurone ce processus s’appelle backpropagation
Réseaux de neurones
- Une neurone
- Une couche de neurone
- Deep learning
Neurone simple
flowchart LR
subgraph X["x"]
x1["x₁"]
x2["x₂"]
x3["x₃"]
x4["x₄"]
end
x1 --> w1["× w₁"]
x2 --> w2["× w₂"]
x3 --> w3["× w₃"]
x4 --> w4["× w₄"]
w1 --> S["Σ"]
w2 --> S
w3 --> S
w4 --> S
S --> F["h"]
F --> Y["y"]
style x1 fill:#F5F5F5, color:#111111, stroke:#111111
style x2 fill:#F5F5F5, color:#111111, stroke:#111111
style x3 fill:#F5F5F5, color:#111111, stroke:#111111
style x4 fill:#F5F5F5, color:#111111, stroke:#111111
style w1 fill:#EBEBEB, color:#666666, stroke:#AAAAAA
style w2 fill:#EBEBEB, color:#666666, stroke:#AAAAAA
style w3 fill:#EBEBEB, color:#666666, stroke:#AAAAAA
style w4 fill:#EBEBEB, color:#666666, stroke:#AAAAAA
style S fill:#111111, color:#FAFAFA, stroke:#111111
style F fill:#111111, color:#FAFAFA, stroke:#111111
style Y fill:#F5F5F5, color:#111111, stroke:#111111
style X fill:#FAFAFA, color:#111111, stroke:#CCCCCC
Un modèle = une fonction à paramètres \(f_\theta\) :
\[Y = f_\theta(X)\]
Ici :
- \(X = (x_1, x_2, x_3, x_4)\)
- \(Y = f(w_1\cdot x_1 + \cdot w_1\cdot x_2 + w_3 \cdot x_3 + w_4\cdot x_4)\)
- \(\theta = (w_1, w_2, w_3, w_4)\) (Les poids)
- \(h\) s’appelle la fonction d’activation
Autrement dit :
- \(f_\theta(X) = h(\theta \cdot X)\) (produit scalaire)
Ou :
- \(f_\theta(X) = h(\theta \cdot X^T)\) (produit matriciel)
Couche de neurones
flowchart LR
subgraph X["x"]
x1["x₁"]
x2["x₂"]
x3["x₃"]
x4["x₄"]
end
subgraph C["couche dense"]
n1["f"]
n2["f"]
n3["f"]
end
subgraph Y["ŷ"]
y1["ŷ₁"]
y2["ŷ₂"]
y3["ŷ₃"]
end
x1 --> n1 & n2 & n3
x2 --> n1 & n2 & n3
x3 --> n1 & n2 & n3
x4 --> n1 & n2 & n3
n1 --> y1
n2 --> y2
n3 --> y3
style x1 fill:#F5F5F5, color:#111111, stroke:#111111
style x2 fill:#F5F5F5, color:#111111, stroke:#111111
style x3 fill:#F5F5F5, color:#111111, stroke:#111111
style x4 fill:#F5F5F5, color:#111111, stroke:#111111
style n1 fill:#111111, color:#FAFAFA, stroke:#111111
style n2 fill:#111111, color:#FAFAFA, stroke:#111111
style n3 fill:#111111, color:#FAFAFA, stroke:#111111
style y1 fill:#F5F5F5, color:#111111, stroke:#111111
style y2 fill:#F5F5F5, color:#111111, stroke:#111111
style y3 fill:#F5F5F5, color:#111111, stroke:#111111
style X fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style C fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style Y fill:#FAFAFA, color:#111111, stroke:#CCCCCC
Un modèle = une fonction à paramètres
\[Y = f_\theta(X)\]
\(X = (x_1, x_2, x_3, x_4)\)
\(Y = (y_1, y_2, y_3)\)
\(\theta = \begin{bmatrix} w_{1,1} & \cdots & w_{1,4} \\ \vdots & \ddots & \vdots \\ w_{3,1} & \cdots & w_{3,4} \end{bmatrix}\)
\(f_\theta(X) = h(\theta \cdot X^T)\)
Et c’est pourquoi l’algèbre linéaire devient importante !
Deep learning
graph LR
subgraph X["x"]
x1["x₁"]
x2["x₂"]
x3["x₃"]
x4["x₄"]
end
subgraph C1["couche 1"]
n11["f"]
n12["f"]
n13["f"]
n14["f"]
n15["f"]
end
subgraph C2["couche 2"]
n21["f"]
n22["f"]
n23["f"]
end
subgraph C3["couche 3"]
n31["f"]
n32["f"]
n33["f"]
n34["f"]
end
subgraph Y["ŷ"]
y1["ŷ₁"]
y2["ŷ₂"]
y3["ŷ₃"]
y4["ŷ₄"]
end
x1 --> n11 & n12 & n13 & n14 & n15
x2 --> n11 & n12 & n13 & n14 & n15
x3 --> n11 & n12 & n13 & n14 & n15
x4 --> n11 & n12 & n13 & n14 & n15
n11 --> n21 & n22 & n23
n12 --> n21 & n22 & n23
n13 --> n21 & n22 & n23
n14 --> n21 & n22 & n23
n15 --> n21 & n22 & n23
n21 --> n31 & n32 & n33 & n34
n22 --> n31 & n32 & n33 & n34
n23 --> n31 & n32 & n33 & n34
n31 --> y1
n32 --> y2
n33 --> y3
n34 --> y4
style x1 fill:#F5F5F5, color:#111111, stroke:#111111
style x2 fill:#F5F5F5, color:#111111, stroke:#111111
style x3 fill:#F5F5F5, color:#111111, stroke:#111111
style x4 fill:#F5F5F5, color:#111111, stroke:#111111
style n11 fill:#111111, color:#FAFAFA, stroke:#111111
style n12 fill:#111111, color:#FAFAFA, stroke:#111111
style n13 fill:#111111, color:#FAFAFA, stroke:#111111
style n14 fill:#111111, color:#FAFAFA, stroke:#111111
style n15 fill:#111111, color:#FAFAFA, stroke:#111111
style n21 fill:#111111, color:#FAFAFA, stroke:#111111
style n22 fill:#111111, color:#FAFAFA, stroke:#111111
style n23 fill:#111111, color:#FAFAFA, stroke:#111111
style n31 fill:#111111, color:#FAFAFA, stroke:#111111
style n32 fill:#111111, color:#FAFAFA, stroke:#111111
style n33 fill:#111111, color:#FAFAFA, stroke:#111111
style n34 fill:#111111, color:#FAFAFA, stroke:#111111
style y1 fill:#F5F5F5, color:#111111, stroke:#111111
style y2 fill:#F5F5F5, color:#111111, stroke:#111111
style y3 fill:#F5F5F5, color:#111111, stroke:#111111
style y4 fill:#F5F5F5, color:#111111, stroke:#111111
style X fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style C1 fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style C2 fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style C3 fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style Y fill:#FAFAFA, color:#111111, stroke:#CCCCCC
linkStyle default interpolate basis
Un modèle = une fonction à paramètres \(f_\theta\) :
\[Y = f_\theta(X)\]
| Modèle | Couches | Dimension cachée |
|---|---|---|
| GPT-2 small | 12 | 768 |
| GPT-2 large | 36 | 1 280 |
| GPT-3 | 96 | 12 288 |
| LLaMA 3 8B | 32 | 4 096 |
| LLaMA 3 70B | 80 | 8 192 |
Réseaux de neurones – Backpropagation
graph LR
subgraph X["x"]
x1["x₁"]
x2["x₂"]
x3["x₃"]
x4["x₄"]
end
subgraph C1["couche 1"]
n11["f"]
n12["f"]
n13["f"]
n14["f"]
n15["f"]
end
subgraph C2["couche 2"]
n21["f"]
n22["f"]
n23["f"]
end
subgraph C3["couche 3"]
n31["f"]
n32["f"]
n33["f"]
n34["f"]
end
subgraph Y["ŷ"]
y1["ŷ₁"]
y2["ŷ₂"]
y3["ŷ₃"]
y4["ŷ₄"]
end
x1 --> n11 & n12 & n13 & n14 & n15
x2 --> n11 & n12 & n13 & n14 & n15
x3 --> n11 & n12 & n13 & n14 & n15
x4 --> n11 & n12 & n13 & n14 & n15
n11 --> n21 & n22 & n23
n12 --> n21 & n22 & n23
n13 --> n21 & n22 & n23
n14 --> n21 & n22 & n23
n15 --> n21 & n22 & n23
n21 --> n31 & n32 & n33 & n34
n22 --> n31 & n32 & n33 & n34
n23 --> n31 & n32 & n33 & n34
n31 --> y1
n32 --> y2
n33 --> y3
n34 --> y4
style x1 fill:#F5F5F5, color:#111111, stroke:#111111
style x2 fill:#F5F5F5, color:#111111, stroke:#111111
style x3 fill:#F5F5F5, color:#111111, stroke:#111111
style x4 fill:#F5F5F5, color:#111111, stroke:#111111
style n11 fill:#111111, color:#FAFAFA, stroke:#111111
style n12 fill:#111111, color:#FAFAFA, stroke:#111111
style n13 fill:#111111, color:#FAFAFA, stroke:#111111
style n14 fill:#111111, color:#FAFAFA, stroke:#111111
style n15 fill:#111111, color:#FAFAFA, stroke:#111111
style n21 fill:#111111, color:#FAFAFA, stroke:#111111
style n22 fill:#111111, color:#FAFAFA, stroke:#111111
style n23 fill:#111111, color:#FAFAFA, stroke:#111111
style n31 fill:#111111, color:#FAFAFA, stroke:#111111
style n32 fill:#111111, color:#FAFAFA, stroke:#111111
style n33 fill:#111111, color:#FAFAFA, stroke:#111111
style n34 fill:#111111, color:#FAFAFA, stroke:#111111
style y1 fill:#F5F5F5, color:#111111, stroke:#111111
style y2 fill:#F5F5F5, color:#111111, stroke:#111111
style y3 fill:#F5F5F5, color:#111111, stroke:#111111
style y4 fill:#F5F5F5, color:#111111, stroke:#111111
style X fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style C1 fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style C2 fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style C3 fill:#FAFAFA, color:#111111, stroke:#CCCCCC
style Y fill:#FAFAFA, color:#111111, stroke:#CCCCCC
linkStyle default interpolate basis
La fonction d’inférence (forward-pass) devient une fonction composée :
\[ \begin{align} y &= f_\theta(x) \\ &= L^3_{\theta_1} \circ L^2_{\theta_2} \circ L^1_{\theta_3}(x) \end{align} \]
La dérivation suit la règle de dérivation en chaîne
\[ \frac{\partial \mathcal{L}}{\partial \theta_3} = \frac{\partial \mathcal{L}}{\partial y} \cdot \frac{\partial L^1}{\partial L^2} \cdot \frac{\partial L^2}{\partial L^3} \cdot \frac{\partial L^3}{\partial \theta_3} \]
En pratique l’optimisation par descente de gradient devient une série de calculs matriciels
Descente de gradient
Problème : minimiser \(\mathcal{L}(\theta)\) — souvent non-convexe, de dimension \(10^9\).
Algorithme :
\[\theta \leftarrow \theta - \eta \cdot \nabla_\theta \mathcal{L}\]
- \(\eta\) — taux d’apprentissage (learning rate)
- \(\nabla_\theta \mathcal{L}\) — gradient calculé par rétropropagation
Rétropropagation = dérivée de la composée (règle de chaîne) :
\[\frac{\partial \mathcal{L}}{\partial w} = \frac{\partial \mathcal{L}}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z} \cdot \frac{\partial z}{\partial w}\]
En pratique : PyTorch calcule tout automatiquement (loss.backward()).
Du texte au vecteur – du vecteur au texte
- Tokenisation
- Embedding
- Logit
Prédiction du token suivant
Objectif : maximiser la probabilité du token suivant
\[P(\text{token}_{t+1} \mid \text{token}_1, \ldots, \text{token}_t)\]
Exemple :
“Bonjour mon …” →
coeur(42%) ·choeur(28%) ·trésor(15%) · … ·choeur(0.0001%) · …\[P(\text{"coeur"} \mid \text{"Bonjour"}, \text{"mon"})\]
Problème fondamental :
- Les mots ne sont pas des nombres. L’optimisation ne fonctionne bien que dans un espace continu. → Il faut une représentation vectorielle des tokens.
Tokenisation et embedding
Pipeline complet :
\[\text{Mots} \xrightarrow{\text{tokenisation}} \text{IDs} \xrightarrow{\text{embedding}} \text{vecteurs} \xrightarrow{\text{attention}} \text{contexte} \xrightarrow{\text{softmax}} P(\text{token suivant})\]
Tokenisation
“Fonctionnement” → ['Fonct', 'ion', 'nement'] → [12043, 287, 3890]
Algorithme BPE (Byte-Pair Encoding) — vocabulaire ~50 000 tokens.
Embedding
Chaque token ID → vecteur de dimension \(d\) (ex. 768, 4096…)
Distance entre vecteurs ≈ similarité sémantique.
roi − homme + femme ≈ reine
Embedding
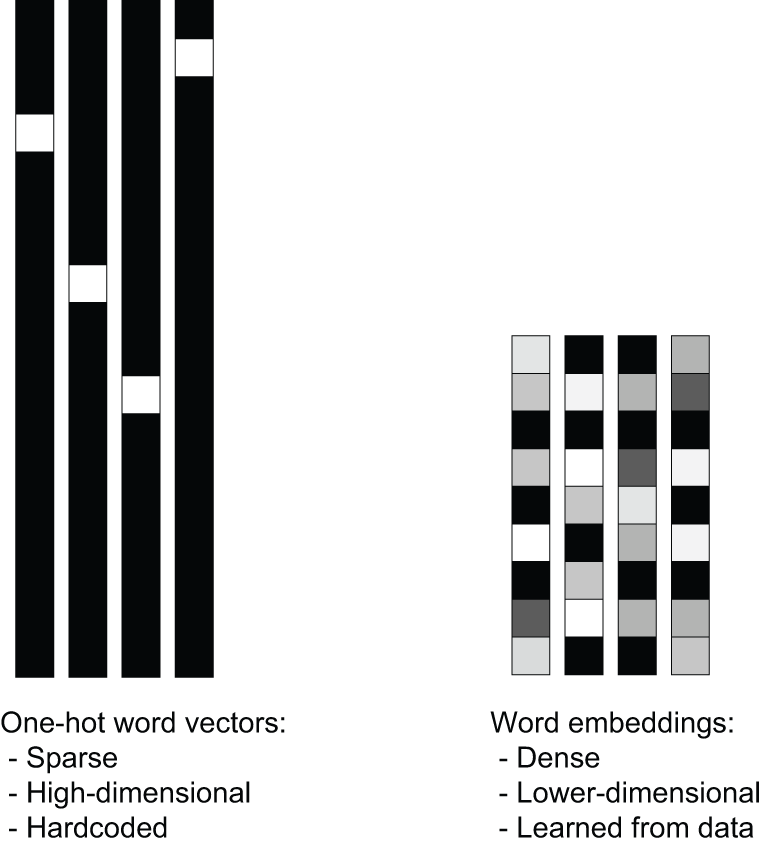
Embedding
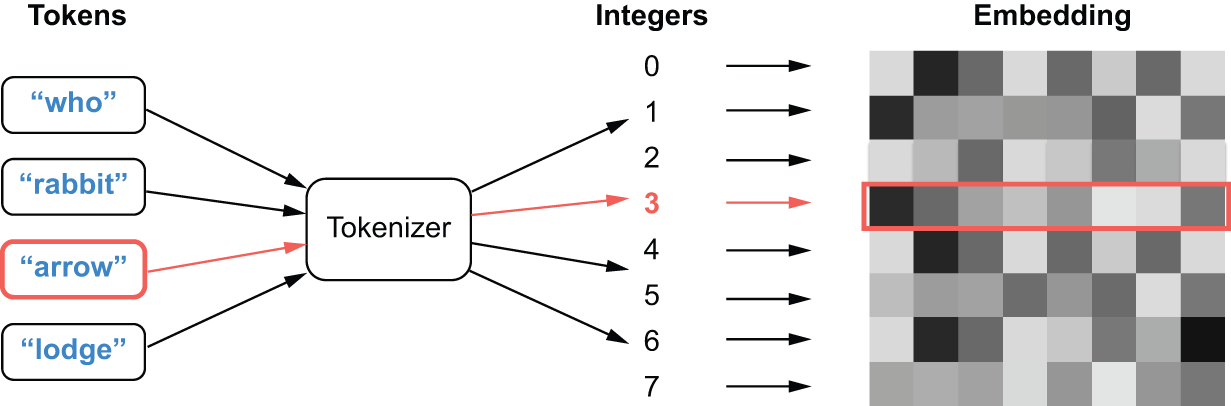
Embedding
Architecture Transformer
L’architecture dominante depuis 2017 (Attention is All You Need, Vaswani et al.)
Mécanisme clé — Self-Attention :
\[\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right) V\]
Chaque token peut “regarder” tous les autres tokens du contexte.
Outils utilisés en pratique :
torch— calcul tensoriel et autogradtransformers— modèles pré-entraînésjax— alternative performante (Google)
GPU et géopolitique
Le lingot d’or de l’IA
 GPU —
GPU —
Pourquoi les GPU ?
CPU — généraliste
- Quelques cœurs puissants (8–32)
- Optimisé pour les tâches séquentielles
- Grande mémoire cache
- Faible parallélisme
Inadapté à la multiplication de matrices à grande échelle.
GPU — spécialisé
- Des milliers de petits cœurs (H100 : 16 896 CUDA cores)
- Optimisé pour les calculs parallèles
- Mémoire HBM très rapide (80 GB, 3.35 TB/s)
- Conçu pour : jeux vidéo → Deep Learning
GPU vs CPU
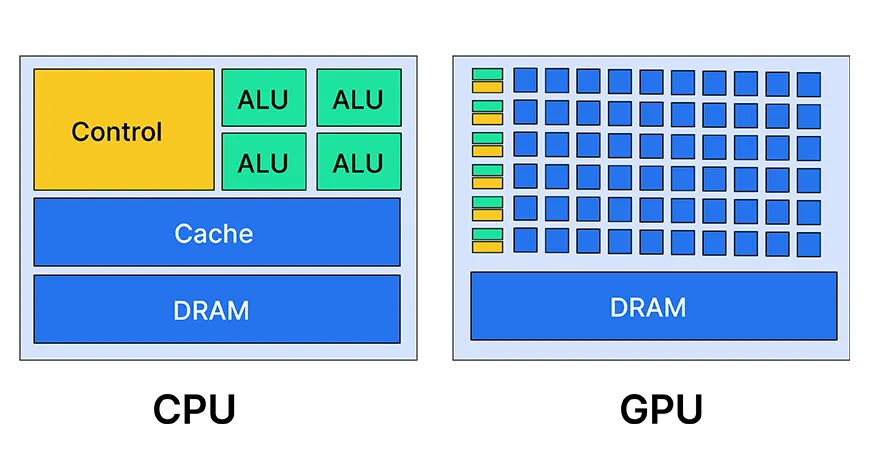
Comparaison des hardwares
| Caractéristique | Apple M5 Max (2026) | NVIDIA RTX 5090 (2025) | NVIDIA H100 SXM (2022) |
|---|---|---|---|
| Usage principal | Laptop pro / IA embarquée | Gaming haut de gamme / IA perso | Datacenter / entraînement LLM |
| Architecture | Apple Silicon (3 nm, TSMC) | Blackwell (4 nm, TSMC) | Hopper (4 nm, TSMC) |
| Nombre de cœurs GPU | 40 cœurs GPU Apple | 21 760 cœurs CUDA | 16 896 cœurs CUDA |
| TFLOPS FP32 | ~20 TFLOPS (estimé) | 125 TFLOPS | 67 TFLOPS |
| TFLOPS FP16 (IA) | ~30 TFLOPS (estimé) | 210 TFLOPS (Tensor FP16) | 1 979 TFLOPS (Tensor FP16) |
| Mémoire (VRAM) | 128 GB unifiée (CPU+GPU) | 32 GB GDDR7 | 80 GB HBM3 |
| Bande passante mém. | ~400 GB/s | 1 792 GB/s | 3 350 GB/s |
| Prix indicatif | ~5 000–7 000 CHF (MacBook) | ~2 000 USD (carte seule) | ~25 000–40 000 USD (carte seule) |
| Consommation | ~80–100 W (tout le SoC) | 575 W | 350–700 W |
| Refroidissement | Passif + ventilateurs laptop | Ventirad dédié (PC de bureau) | Refroidissement liquide (serveur) |
| Contexte d’usage IA | LLM <30B en local, inference | LLM <30B en local, fine-tuning | Entraînement GPT-4, clusters |
Coût de calcul
| Modèle | Paramètres | GPU-heures (entraînement) | Coût estimé |
|---|---|---|---|
| GPT-2 (2019) | 1.5 B | ~300 | < 50 k$ |
| LLaMA 1 7B (2023) | 7 B | 82 432 | ~500 k$ |
| GPT-4 (2023, estimé) | ~1 800 B | > 25 M | > 100 M$ |
| Llama 4 Scout (2025) | 109 B | ~5 M | > 50 M$ |
Inférence (générer 1 réponse) : bien moins coûteux — mais multiplié par des milliards de requêtes.
Fermes de GPU et investissements
| Acteur | Infrastructure | Investissement annoncé |
|---|---|---|
| Microsoft / OpenAI | Azure (>400 k GPU H100) | 80 G$ (2025) |
| Google DeepMind | TPU v5 (propriétaire) | 75 G$ (2025) |
| Meta | 350 k GPU H100 | 65 G$ (2025) |
| xAI (Elon Musk) | Colossus — Memphis | 6 G$ |
Une seule puce H100 = env. 30 000 $ · délai de livraison : 6–12 mois (2023–2024)
Tensions géopolitiques
Export Control Act (USA)
- Restriction des puces NVIDIA A100/H100 vers la Chine depuis 2022
- Les GPU sont devenus un outil de politique étrangère
- Terres rares : dépendance minière (Congo, Chine, Australie)
Conséquence : course aux fournisseurs alternatifs, puces souveraines (EU Chips Act)
DeepSeek — janvier 2025
Modèle chinois entraîné malgré les restrictions :
- DeepSeek-R1 : performances ≈ GPT-4o
- Entraînement avec H800 (version bridée autorisée)
- Techniques d’optimisation agressives (MoE, MLA)
- Open-source — impact mondial immédiat
→ La restriction d’accès aux puces accélère l’innovation locale.
En Conclusion
- Quiz
- Lecture
Quiz 5
- Expliquer comment les tensions sur les terre rares entre la Chine et les États-Unis sont liées aux mathématiques des réseaux de neurones.
- Expliquer comment le texte est transformé en vecteur par les LLMs et pourquoi.
- Faire un diagramme d’un réseau de Deep Learning et montrer comment il se traduit en termes mathématiques.
Pour jeudi
- TP 4 — Entraînement d’un LLM
- Lecture 5 — Artificial Intelligence Index Report 2025
Questions pour la Lecture 5 :
- Dans les pages 3, 4 et 5, les auteurs donnent les douze conclusions principales du rapport. En choisir 5 et illustrez chacune avec un exemple concret.